Learning Cross-Scale Visual Representations for Real-Time Image Geo-Localization
Abstract
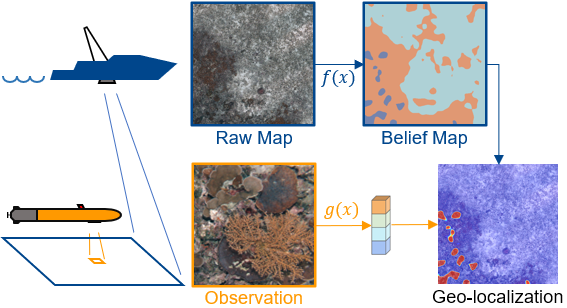
Robot localization remains a challenging task in GPS denied environments. State estimation approaches based on local sensors, e.g. cameras or IMUs, are drifting-prone for long-range missions as error accumulates. In this study, we aim to address this problem by localizing image observations in a 2D multi-modal geospatial map. We introduce the cross-scale dataset and a methodology to produce additional data from cross-modality sources. We propose a framework that learns cross-scale visual representations without supervision. Experiments are conducted on data from two different domains, underwater and aerial. In contrast to existing studies in cross-view image geo-localization, our approach a) performs better on smaller-scale multi-modal maps; b) is more computationally efficient for real-time applications; c) can serve directly in concert with state estimation pipelines.
Published at: RA-L 2022, ICRA 2022